互联网公司运维模式全景图
传统IDC运维:稳态业务的最后堡垒
- **适用场景**:金融核心账务、政企私有云 - **核心特征**: - 物理服务器+专线网络,变更窗口严格 - 故障处理依赖“人肉”登录,脚本散落在个人电脑 - **痛点**:扩容周期长、资源利用率低于30%、变更风险高 ---云原生运维:弹性与成本的最优解
- **技术栈**:Kubernetes、Service Mesh、Serverless - **优势**: - **分钟级扩缩容**:双十一峰值流量自动弹起数千Pod - **成本节省40%**:通过Spot实例+混部超卖 - **挑战**: - 微服务数量爆炸,排障链路复杂 - 需要重新设计监控指标(如P99延迟而非平均延迟) ---SRE:用软件工程解决运维问题
- **Google提出的核心公式**: **“运维工作 = 琐事 + 工程化”** - **落地三板斧**: 1. **错误预算**:每月允许系统不可用时间为0.1%,倒逼开发优化 2. **SLI/SLO**:将“用户体验”量化为“购物车接口99.9%请求<200ms” 3. **自动化武器库**:Chaos Engineering、自动回滚、金丝雀发布 ---DevOps:打破开发与运维的“柏林墙”
- **文化层面**: - 开发对线上故障负全责(“谁构建,谁运行”) - 每周固定“无会议日”让工程师专注自动化 - **工具链实践**: - **CI**:GitLab Runner并行执行单测+安全扫描(10分钟反馈) - **CD**:Argo CD基于GitOps的声明式部署,回滚只需git revert - **可观测性**:Prometheus+Grafana+Jaeger三板斧,定位问题从小时级降到分钟级 ---AIOps:让机器处理机器的问题
- **典型场景**: - **异常检测**:通过LSTM模型预测磁盘故障,提前72小时预警 - **根因分析**:利用知识图谱关联变更事件与指标异常,减少MTTR 50% - **落地陷阱**: - 数据质量差导致模型误报(如未清洗的测试环境数据) - 需要预留“人工兜底”通道,避免AI决策失误引发雪崩 ---如何落地DevOps?从0到1的七步路线图
Step1:评估现状——先止血再优化
- **诊断清单**: - 部署频率:是否低于每月1次? - 故障恢复时间:是否超过1小时? - 变更失败率:是否高于10%? - **工具**:使用DORA问卷快速打分(https://dora.dev/) ---Step2:组建跨职能小队——“披萨团队”原则
- **规模**:6-8人(两张披萨能吃饱) - **角色配比**: - 1名SRE(负责基础设施) - 2名后端+1名前端+1名QA+1名产品经理 - **OKR示例**: - 季度目标:将部署耗时从2小时缩短到15分钟 ---Step3:搭建最小可行工具链
- **技术选型避坑**: - **CI工具**:Jenkins vs GitLab CI——后者内置容器注册表,减少集成成本 - **制品库**:Nexus支持Docker镜像+npm包统一管理 - **流水线设计**: ``` 代码提交 → 单测 → 构建镜像 → 安全扫描 → 部署到测试环境 → 自动化E2E测试 ``` ---Step4:定义“完成”标准——DoD的颗粒度
- **示例**: - 功能代码合并前需满足: - 单测覆盖率>80% - 性能基准测试通过(API P95延迟<100ms) - 已更新Runbook(包含回滚命令) ---Step5:渐进式发布策略
- **灰度方案对比**: | 策略 | 技术实现 | 适用场景 | |------------|------------------------|------------------------| | 蓝绿部署 | 双集群流量切换 | 支付系统等零容忍业务 | | 金丝雀 | Istio按权重分流5%流量 | 新功能A/B测试 | | 功能开关 | LaunchDarkly动态配置 | 紧急关闭高风险特性 | ---Step6:建立反馈闭环——让数据说话
- **关键指标看板**: - **部署前置时间**:从代码提交到生产环境耗时 - **变更失败率**:导致服务降级的部署占比 - **MTTR**:故障平均恢复时间 - **复盘模板**: - 故障标题:用户支付超时5分钟 - 根因:数据库索引缺失导致全表扫描 - 改进:增加索引+预生产环境压测流程 ---Step7:文化固化——从“项目”到“产品”思维
- **激励机制**: - 每月评选“最佳自动化脚本”,奖励技术大会门票 - 将SRE纳入绩效评审,与开发共同背SLA指标 - **反模式警示**: - **“DevOps工程师”成为新孤岛**:要求开发自己写Dockerfile - **过度追求工具炫酷**:Kubernetes集群管理3台服务器 ---常见疑问快问快答
**Q:小公司没有专职SRE能否落地DevOps?** A:可以。让资深后端兼任SRE职责,初期聚焦自动化部署和监控告警,随着业务增长再拆分团队。 **Q:如何说服管理层投入DevOps?** A:用数据对比:展示同行通过DevOps将发布频率提升20倍、故障减少75%的案例(如Etsy的公开报告)。 **Q:工具链太多如何选型?** A:遵循“3年生命周期”原则:优先选择云厂商托管服务(如AWS CodePipeline),减少维护成本。 ---未来演进:从DevOps到DevSecOps
- **安全左移**:在CI阶段集成SAST(如SonarQube)和DAST(如OWASP ZAP) - **供应链安全**:使用Sigstore对容器镜像签名,防止Log4j类漏洞 - **政策即代码**:通过OPA(Open Policy Agent)强制要求所有镜像无高危漏洞才能部署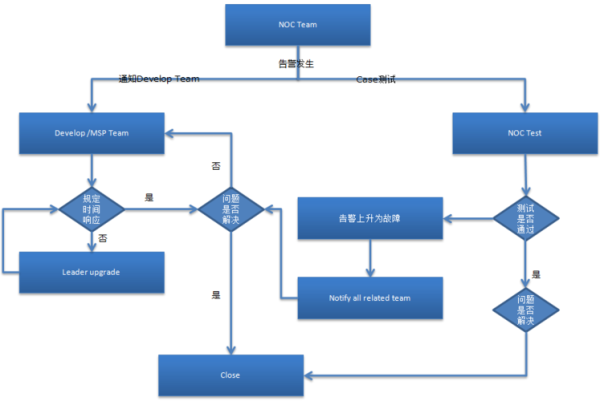
(图片来源网络,侵删)
评论列表