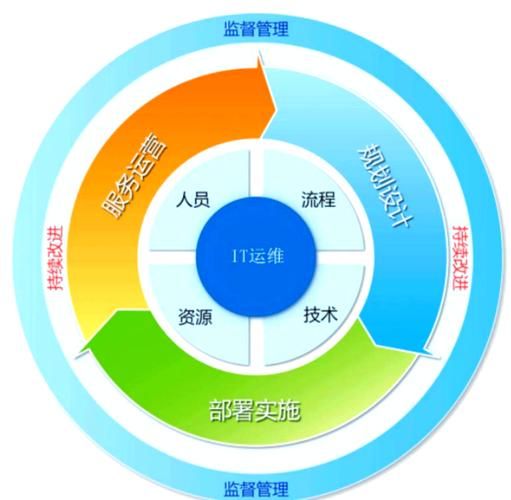
互联网运维到底在“运”什么?
很多刚入行的新人把运维简单理解为“修电脑、装系统”,其实互联网运维的核心是保障业务连续性、提升交付效率、降低故障成本。它覆盖从代码提交到用户访问的整条链路,包括:
(图片来源网络,侵删)
- 基础设施:服务器、网络、IDC、云资源
- 中间件:消息队列、缓存、数据库、网关
- 应用:容器、微服务、Serverless
- 观测:日志、指标、链路追踪、告警
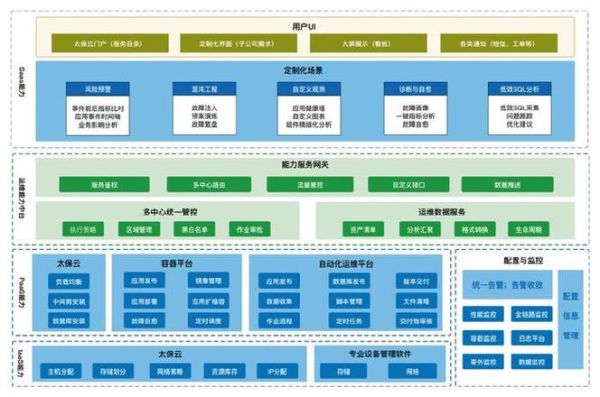
主流互联网运维模式全景图
1. 传统IOE模式(IBM/Oracle/EMC)
特点:集中式、商用软硬件、纵向扩展
适用:金融、电信等对稳定性极端敏感的场景
痛点:成本高、扩展慢、创新乏力
2. DevOps模式
核心:开发运维一体化,CI/CD贯穿始终
关键实践:GitLab CI + Jenkins + Docker + K8s
落地难点:组织文化、自动化测试覆盖率、灰度发布策略
3. SRE(Site Reliability Engineering)
Google提出,用软件工程方法做运维
关键指标:SLI/SLO/Error Budget
典型工具:Prometheus + Grafana + Alertmanager
落地经验:把“运维需求”写成User Story,纳入迭代
4. NoOps(Serverless极致)
理念:开发者只关心代码,其余交给云厂商
代表:AWS Lambda、阿里云函数计算
注意:并非“零运维”,而是运维责任转移,仍需监控与成本治理
5. ChatOps
把运维操作搬到聊天工具(飞书、钉钉、Slack)
好处:操作可审计、知识沉淀、降低门槛
落地:Hubot + 自定义Webhook + 权限管控
(图片来源网络,侵删)
如何根据企业规模选择运维模式?
初创公司(<50人)
- 直接上云,选全托管PaaS(云数据库、Serverless网关)
- 监控用云厂商自带,告警先打通钉钉群
- 一个运维+一个后端就能跑
成长型公司(50-500人)
- 自建K8s,但核心中间件仍用云托管(如阿里云RocketMQ)
- 引入SRE小组,先对支付、登录等黄金链路设SLO
- CI/CD用GitLab Runner,灰度发布基于Argo Rollouts
大型互联网公司(>500人)
- 混合云:自建IDC+多云调度,K8s联邦集群
- 自研PaaS平台,封装底层差异,提供声明式API
- FinOps团队专门做成本优化,每月节省千万级
落地互联网运维模式的七步曲
- 现状梳理:用一周时间跑完资产盘点,输出CMDB
- 痛点排序:故障TOP、发布耗时、资源利用率三张表
- 选型验证:用PoC环境跑通最小闭环,记录性能基线
- 组织调整:成立平台组、SRE组、业务运维组,职责边界写进OKR
- 自动化切入:从最高频的“重启+扩容”脚本开始,逐步替换人工
- 度量驱动:把MTTR、变更成功率、资源成本写进周报
- 持续迭代:每季度Review一次,淘汰低ROI工具
常见疑问解答
Q:DevOps和SRE冲突吗?
不冲突。DevOps是文化运动,SRE是具体岗位;DevOps解决“协作”问题,SRE解决“可靠性”问题。
Q:小公司需要SRE吗?
可以设“兼职SRE”,让资深后端承担可靠性Owner,先对核心接口设SLO,再逐步扩大范围。
Q:Serverless会取代K8s吗?
不会。Serverless适合事件驱动、弹性大的场景;K8s适合长连接、状态ful服务。未来五年是并存状态。
2024年值得关注的运维新趋势
- eBPF全链路可观测:零侵入抓包,定位网络延迟到微秒级
- Platform Engineering:把K8s包装成“自助式PaaS”,让开发秒建环境
- FinOps工具链:自动识别闲置EIP、低水位RDS,一键降配
- AIOps智能降噪:用LLM聚合相似告警,减少99%噪音
实战案例:某电商大促如何抗住百万QPS
背景:双11峰值预估百万QPS,历史曾出现库存超卖
方案:
(图片来源网络,侵删)
- 提前三个月做容量压测,用ChaosBlade注入网络延迟,发现Redis连接池瓶颈
- 引入云原生网关(Higress),把南北向流量与业务K8s解耦,单机QPS提升3倍
- 库存服务改异步扣减:先写消息队列,再落DB,超卖率降到0
- 大促当天,SRE值班用ChatOps一键扩容,整个过程钉钉群可见,无需登录服务器
最后的话
互联网运维没有银弹,先想清楚业务阶段,再选合适模式。把每一次故障都当成迭代输入,把每一次发布都当成练兵机会,半年后你会感谢现在踏实的自己。
评论列表