全球互联网数据总量到底有多大?
IDC最新《Global DataSphere》报告给出的数字是:2023年全球产生、复制、消费的数据总量约120ZB,相当于12万EB或1.2亿PB。换算成更直观的TB,就是1.2×10¹¹ TB,也就是1200亿TB。
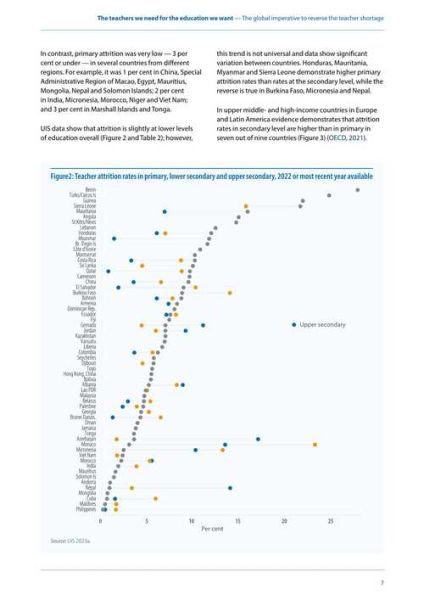
为什么用ZB而不是TB来计量?
TB、PB、EB、ZB之间的进制都是1024倍,当数字大到一定程度,继续用TB表达会让阅读者瞬间失去数量感。举例:
- 1ZB≈10⁹TB
- 全球每年新增120ZB,相当于每秒新增3.8万TB
因此,行业报告统一采用ZB为单位,既简洁又避免天文数字带来的认知负荷。
哪些因素在推高数据总量?
1. 高清与超高清视频
Netflix、TikTok、YouTube三家在2023年就贡献了全球约60%的下行流量。4K视频码率35Mbps,8K则高达100Mbps,每增加一个用户,数据量呈指数级放大。
2. 物联网设备激增
GSMA统计,全球蜂窝物联网连接数已突破30亿。一辆自动驾驶测试车每天产生5TB原始传感器数据,城市级车联网瞬间就能把PB级数据推上云端。
3. 生成式AI训练与推理
训练一次GPT-4规模的模型,仅语料存储就需数PB;推理阶段,每次对话请求背后都涉及GB级的向量检索与缓存。
如何自己估算一个细分场景的数据量?
以“全球每天新增短视频”为例,拆解思路:
- 取TikTok官方披露日活15亿,人均上传0.8条短视频。
- 平均每条视频15秒,1080p码率8Mbps。
- 单条体积:8Mbps×15s÷8=15MB。
- 全球日新增:15亿×0.8×15MB≈18PB。
- 再计入备份、CDN多副本、转码多清晰度,放大系数取5倍,最终90PB/日。
通过同样的乘法模型,你可以快速评估任何垂直场景的数据规模。
数据总量与存储成本的关系
AWS S3标准存储月单价约0.023美元/GB,120ZB若全部放在公有云,每月仅存储费用就高达2760亿美元,相当于瑞士全年GDP。因此,企业普遍采用:
- 冷热分层:7天内热数据放SSD,30天以上冷数据放对象存储,90天以上归档到磁带。
- 去重与压缩:日志文本可压缩至原体积10%,虚拟机镜像去重后节省50%空间。
- 边缘缓存:把TOP 20%热点内容下沉到边缘节点,骨干流量可下降70%。
未来五年数据总量还会翻几倍?
IDC预测,到2027年全球数据总量将达284ZB,年复合增长率23%。驱动力主要来自:
- 8K/VR内容普及,单小时体积突破50GB。
- 工业数字孪生,每个工厂每天产生1TB实时仿真数据。
- 医疗基因测序,单次全基因组数据200GB,年测序人次破10亿。
若保持现有增速,2030年前后我们将迎来YB级(1000ZB)时代。
个人站长如何应对数据洪峰?
流量小站也许永远达不到ZB级,但单点PB级已近在眼前。可落地的动作清单:
- 日志轮转:Nginx日志按天切割,7天后打包压缩,30天后上传OSS归档。
- 图片WebP化:同画质下体积减少30%,CDN流量直接下降。
- 数据库分片:单表过5000万行即考虑水平拆分,避免InnoDB膨胀到TB级。
- 对象存储生命周期:设置“30天转低频、180天转归档”,自动降低成本。
数据总量膨胀带来的SEO新机会
搜索引擎需要处理的内容越多,高质量稀缺内容的价值就越高。具体策略:
- 结构化数据:用Schema.org标记FAQ、HowTo,让机器秒懂语义。
- 长尾词深耕:在ZB级噪声里,月搜索量<100的长尾往往竞争极低。
- 实时内容:数据流越大,时效性权重越高,热点发布后5分钟内被索引可获额外曝光。
常见疑问快答
问:1ZB到底能存多少部1080p电影?
答:按每部1080p电影8GB计算,1ZB≈125亿部,全球每人可分16部。
问:为什么我的网站日志才几百GB,云账单却显示用了几TB?
答:云厂商默认多可用区冗余,3副本起步,再加上定期快照,实际占用是原始体积的3~5倍。
问:数据总量这么大,SEO还有红利吗?
答:总量越大,噪音越大,信号越稀缺。坚持E-E-A-T原则,持续输出深度内容,反而更容易脱颖而出。
评论列表