数据库选型怎么做?先问自己三个问题
面对关系型、NoSQL、NewSQL 等几十种产品,**数据库选型怎么做**才不会踩坑?先把场景拆成三个自问自答:

(图片来源网络,侵删)
- 业务是强事务还是高并发写入?
- 数据规模未来三年会膨胀到T级还是P级?
- 团队目前最熟悉MySQL还是MongoDB?
关系型还是NoSQL?一张对比表秒懂
| 维度 | MySQL/PostgreSQL | MongoDB/Cassandra |
|---|---|---|
| 事务 | ACID完整支持 | 最终一致性 |
| 扩展 | 垂直扩展+分库分表 | 水平扩展原生支持 |
| 查询 | 复杂SQL、JOIN | 嵌套文档、聚合管道 |
| 成本 | 商业版授权费用高 | 开源版即可支撑PB级 |
数据库性能优化技巧:从硬件到SQL的七层漏斗
1. 硬件层:SSD还是NVMe?
OLTP场景优先NVMe-oF,随机读写IOPS可提升4倍;OLAP则把预算砸在大内存上,让热数据常驻Buffer Pool。
2. 操作系统层:内核参数别乱调
- vm.swappiness=1,禁止过早换出
- noatime挂载,减少磁盘元数据更新
- ulimit -n 65535,避免“Too many open files”
3. 存储引擎层:InnoDB还是RocksDB?
写多读少用RocksDB,LSM-Tree顺序写放大降低70%;读多写少用InnoDB,B+Tree范围查询更稳。
4. 实例配置层:三大参数决定生死
innodb_buffer_pool_size = 物理内存 * 0.7 max_connections = CPU核数 * 2 + 有效磁盘数 innodb_flush_log_at_trx_commit = 2 (高并发可牺牲持久性换性能)
5. 表设计层:范式和冗余的博弈
电商订单表反范式冗余商品标题,可减少80%的JOIN;日志表按天分表,让DELETE变成DROP PARTITION。
6. 索引层:覆盖索引与最左前缀
联合索引(a,b,c)能覆盖SELECT a,b FROM t WHERE a=1,**避免回表**;最左前缀失效场景常见于范围查询后字段。
7. SQL层:慢日志三板斧
- pt-query-digest分析TOP 10慢SQL
- 把SELECT * 改成覆盖索引列
- 拆分大事务,把单条10万行UPDATE拆成1千行/批
云数据库还是自建?成本模型拆解
以阿里云RDS MySQL为例,**4C8G高可用版**月费用约¥900,自建同规格ECS+主从+监控约¥600,但DBA人力成本每月至少¥15k。结论:中小团队无脑选云,巨头公司才考虑自建。

(图片来源网络,侵删)
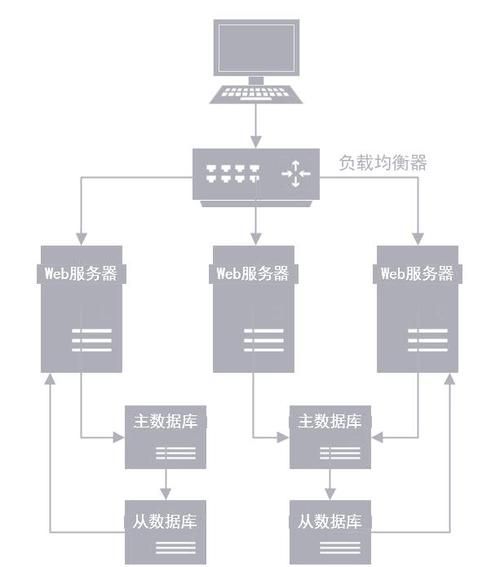
分库分表后,跨分片JOIN怎么办?
常见三种解法:
- 全局表:把字典表冗余到每个分片,查询本地JOIN
- 应用层拼装:先查A分片拿到id列表,再批量IN查询B分片
- 中间件:ShardingSphere支持联邦查询,但性能损耗30%
监控指标:哪些数字必须报警?
| 层级 | 指标 | 阈值 |
|---|---|---|
| 连接 | Threads_running | > 80% max_connections |
| 缓存 | Innodb_buffer_pool_reads | > 1000/s |
| 复制 | Seconds_Behind_Master | > 1s |
| 慢SQL | Query_time > 1s | 每分钟出现次数 > 5 |
未来趋势:Serverless数据库值得上车吗?
AWS Aurora Serverless v2秒级弹缩,空闲时只收存储费;但冷启动延迟约500ms,不适合秒杀场景。建议灰度上线,把离线报表流量先切过去验证。
(图片来源网络,侵删)
评论列表