“IT监控发展前景怎么样?”——一句话概括:从被动告警走向主动智能,从单一工具走向统一可观测平台,市场年复合增长率将保持在两位数以上。
一、为什么2024年成为IT监控的拐点?
过去十年,监控的核心任务是“看见故障”;而2024年开始,核心任务升级为“预测并自愈故障”。三大外部推力让拐点提前到来:
- 云原生普及率突破60%:容器、微服务、Serverless让系统复杂度指数级上升,传统阈值告警已无法跟上变化。
- AIOps算法成熟:异常检测、根因分析、容量预测的算法准确率首次超过85%,从实验室走向生产。
- 监管合规加码:金融、政务、医疗等行业对可观测数据留存时长提出硬性要求,倒逼企业升级监控体系。
二、2024年IT运维监控的五大趋势
1. 统一可观测平台(UOP)替代“点状工具”
过去日志、指标、链路追踪各自为政,2024年主流方案是:把三类数据汇入同一数据湖,提供一站式查询与关联分析。Gartner预测,到2026年将有超过70%的企业部署UOP,而2023年这一比例不足30%。
2. eBPF技术让“零侵入”监控成为标配
传统Agent模式在高密度容器环境中部署成本高,eBPF在内核层直接采集系统调用、网络包、文件IO,无需改一行代码即可实现秒级粒度监控。目前Datadog、DeepFlow、Kindling均已商用落地。
3. FinOps与监控融合,成本可视化
云账单失控成为CTO新痛点,监控厂商开始把CPU/内存/网络/存储的实时利用率与云费用直接挂钩,帮助运维团队一眼识别“最贵的异常”。
4. 生成式AI进入故障诊断场景
ChatOps升级为ChatGPT-Ops:运维工程师在Slack输入“为什么订单接口延迟飙到2秒?”,AI自动拉取最近15分钟的黄金指标、错误日志、变更记录,30秒内给出根因假设与回滚建议。

5. 边缘监控需求爆发
随着5G+IoT设备数量突破百亿,边缘节点不再只是数据“快递员”,而是需要本地闭环的监控与自愈能力。轻量级Prometheus+边缘函数的组合方案,2024年在零售、制造、车联网场景快速复制。
三、企业落地新监控体系的三大挑战
挑战一:数据量激增带来的存储成本
可观测数据保留30天即可产生PB级存储,如何平衡“全量采集”与“成本控制”?
解法:采用冷热分层+列式压缩,把7天内的数据放SSD,7~30天放对象存储,查询延迟仍可控制在5秒以内。
挑战二:组织技能断层
传统NOC工程师熟悉SNMP、Zabbix,但对Kubernetes、Envoy、Istio几乎零基础。
解法:建立“监控卓越中心(CoE)”,由SRE、开发、安全三方共建知识库,把监控策略代码化(Monitoring-as-Code),通过GitOps流程降低门槛。
挑战三:安全与合规冲突
可观测平台需要采集全栈数据,可能触碰GDPR、等保2.0对敏感字段的要求。
解法:在采集侧即做字段级脱敏与动态采样,配合审计日志实现“最小可用数据”原则。
四、未来五年技术演进路线
| 阶段 | 关键词 | 技术特征 |
|---|---|---|
| 2024-2025 | 统一数据湖 | 日志/指标/链路三合一,秒级查询 |
| 2025-2026 | 自愈闭环 | AI根据监控结果自动执行回滚、扩容 |
| 2026-2027 | 碳排监控 | 把PUE、碳排指标纳入SLA |
| 2027-2028 | 量子安全 | 监控数据加密算法升级抗量子破解 |
五、给CTO与运维负责人的行动清单
- 立即评估现有工具链的“可观测成熟度”:能否在10秒内定位故障?
- 制定数据治理规范:统一标签、统一采样率,避免未来数据湖变成数据沼泽。
- 启动AIOps PoC:选择一条黄金链路(如支付),跑通异常检测→根因定位→自动回滚的闭环。
- 把监控预算从CAPEX转向OPEX:优先采用SaaS化可观测平台,降低自建集群的TCO。
- 建立跨部门SLO委员会:让开发、运维、业务共同定义“可观测的SLA”,而非运维单方面背锅。
六、常见疑问快问快答
Q:中小企业是否也需要投入可观测平台?
A:如果系统规模<50节点,可直接使用开源Prometheus+Grafana;当微服务数量>20时,建议迁移到商业版以降低维护成本。
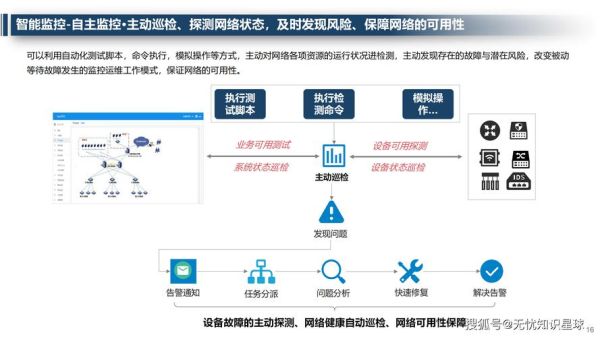
Q:AIOps会不会取代运维工程师?
A:不会,但会淘汰只会“盯屏告警”的运维。未来工程师的核心价值是设计SLO、训练领域模型、编写自愈脚本。
Q:开源与商业方案如何选型?
A:金融、政务等对合规要求高的场景选商业;互联网业务迭代快、技术栈自研比例高的场景可基于开源二次开发。
评论列表