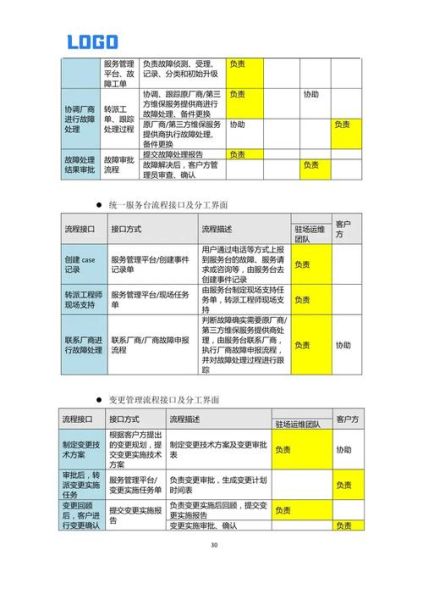
一、为什么网站运维管理越来越重要?
在流量红利见顶的当下,**“稳定性”就是竞争力”**。一次宕机不仅损失订单,还会被搜索引擎降权。运维管理的价值,已经从“修机器”升级为“保增长”。

(图片来源网络,侵删)
1. 业务视角:稳定性直接影响收入
- 电商大促期间,**每宕机1分钟平均损失10万+**
- 金融类站点,SLA低于99.9%会被监管约谈
2. 技术视角:复杂度呈指数级上升
- 微服务、容器、多云架构让故障链路变长
- 传统“人肉”排查已无法应对分钟级恢复要求
二、网站运维管理怎么做?从零到一的落地路径
1. 先搭监控,再谈自动化
很多团队一上来就搞自动化发布,结果监控盲区导致故障找不到根因。**正确的顺序是:监控→告警→自愈→自动化**。
- 监控:覆盖基础设施、应用、业务三层
- 告警:基于“黄金指标”(延迟、流量、错误、饱和度)配置
- 自愈:脚本化重启、降级、扩容
- 自动化:灰度发布、无人值守变更
2. 建立“故障画像”库
把历史故障抽象成模板,下次遇到相似现象直接匹配。**例如**:
【画像A】CPU飙高+FullGC频繁→大概率是热点缓存未预热 【画像B】502错误+上游连接超时→检查Nginx upstream配置
3. 用SLO替代SLA
SLA是“对外承诺”,SLO是“对内目标”。**例如**:
- SLA:全年可用性99.9%
- SLO:核心接口P99延迟<500ms,错误率<0.1%
通过SLO拆解,团队能聚焦真正影响用户的指标。
三、常见故障如何快速定位?三板斧方法论
1. 第一斧:看监控大盘
优先确认是**全局故障还是局部故障**:
(图片来源网络,侵删)
- 全局:CDN、DNS、网关层问题
- 局部:某机房、某服务、某数据库
工具推荐:**Grafana+Prometheus做实时监控**,SkyWalking做链路追踪。
2. 第二斧:查变更记录
90%的故障由变更引发。**排查顺序**:
- 最近1小时是否有发布?
- 配置中心是否推送了动态配置?
- 云厂商是否有维护公告?
小技巧:**用Git commit时间戳关联监控告警时间**,快速锁定可疑变更。
3. 第三斧:模拟用户请求
用curl或Postman直接请求接口,**绕过前端和CDN**,观察:
- 是否返回5xx错误?
- 响应头是否有特殊标记(如X-Cache: MISS)?
- TCP握手耗时是否异常?
四、高频故障场景与应急剧本
场景1:数据库连接池耗尽
现象:应用日志出现“Cannot get connection”
(图片来源网络,侵删)
应急剧本:
- 立即重启应用释放连接(治标)
- 检查慢SQL,优化索引(治本)
- 调整连接池参数:maxActive=CPU核数*2+1
场景2:Redis缓存雪崩
现象:大量请求打到数据库,数据库CPU飙升
应急剧本:
- 启用本地缓存(如Guava)兜底
- 对空值设置短过期时间(如30秒)
- 缓存预热脚本批量加载热点Key
场景3:Nginx 502 Bad Gateway
现象:静态资源正常,动态接口502
应急剧本:
- 检查upstream后端服务是否存活
- 查看Nginx错误日志:是否出现“no live upstreams”
- 临时摘掉故障节点,重启后端服务
五、如何降低故障复发率?三个长效机制
1. 每周故障复盘会
强制要求:**不追责,但需回答三个问题**:
- 故障原因是否可自动化检测?
- 应急预案是否可操作?
- 同类问题是否已全网扫描?
2. 混沌工程常态化
每月随机杀死一台容器或断开一个机房网络,**验证系统韧性**。工具推荐:
- Chaos Mesh(K8s环境)
- Gremlin(多云环境)
3. 建立“运维日历”
把大促、节假日、发薪日等**高流量事件**提前标注,提前扩容、封网、预演。
六、未来趋势:AIOps能否取代人工?
目前AIOps在**异常检测、根因分析**上表现较好,但**决策仍需人工介入**。建议:
- 先用AI做数据降噪(如过滤误报告警)
- 逐步开放“一键止损”权限给AI
- 保留人工兜底按钮
典型案例:**阿里云ARMS通过机器学习将故障定位时间从30分钟缩短到5分钟**。
评论列表