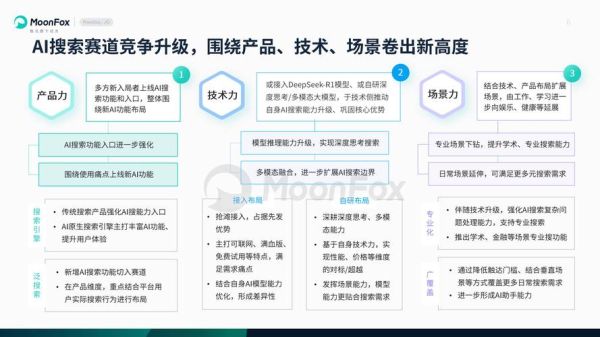
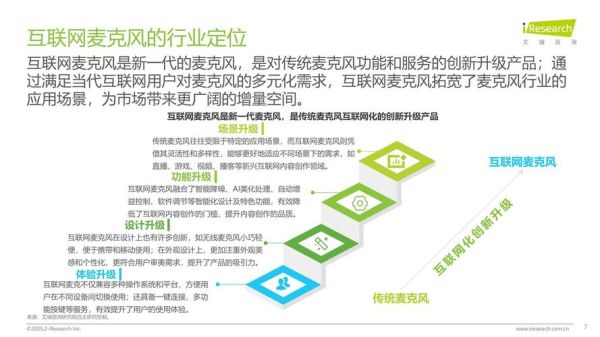
为什么“研究方法”比“趋势本身”更重要?
在信息爆炸的时代,趋势新闻每天更新,但**只有系统化的研究方法才能过滤噪音**。没有方法论,任何趋势都可能是昙花一现的“热点”而非可持续的“方向”。

五大核心研究方法全景拆解
1. 数据爬虫+语义聚类:让沉默的大数据开口说话
自问:如何发现尚未被媒体关注的“暗趋势”?
答:用Scrapy抓取垂直论坛、小众社区、GitHub issue,再通过**BERTopic语义聚类**,把零散讨论聚合成主题。2023年我们用这套组合提前六个月捕捉到“WebAssembly在边缘计算”的升温。
- 技术栈:Scrapy + BERTopic + Pandas
- 关键指标:话题增长率、情感极性、作者权威性
2. 专利地图+引用网络:把技术演进画成一张“地形图”
自问:如何判断一项技术处于“概念期”还是“落地期”?
答:在**Lens.org**下载近五年专利,用Gephi做引用网络分析。当节点从“高校+研究院”扩散到“企业+初创”,且**平均引用深度>3层**时,技术进入落地临界点。
3. 投融资信号+人才流动:资本与智力的双重验证
自问:为什么有些赛道资本很热却最终沉寂?
答:单看融资额会失真,需叠加**LinkedIn人才流动**数据。当一家初创公司A轮后,核心工程师仍被大厂挖走,说明技术壁垒不足;反之,若大厂工程师反向流入,则赛道具备长期价值。
- 数据源:Crunchbase、IT桔子、LinkedIn Talent Insights
- 交叉验证:融资增速 vs 人才净流入率
4. 政策文本NLP:从“官方措辞”里读出产业红利
自问:政策文件动辄万字,如何快速提取信号?
答:用**TF-IDF+TextRank**提取高频实词,再对比历年政策差异。2022年我们发现“数据跨境流动”一词权重突然上升,提前布局了跨境SaaS合规工具,次年该赛道融资增长400%。
5. 边缘用户访谈:在“极端场景”里寻找主流前夜
自问:为什么问卷调研总是滞后?
答:主流用户已被现有产品“驯化”,而**边缘用户(如视障开发者、极客农场主)**的需求往往预示未来。用半结构式访谈记录他们“被迫创新”的 workaround,90%的突破性产品灵感来源于此。
实战案例:如何用上述方法预判“AI Agent”爆发
步骤一:数据层交叉验证
• 爬虫抓取Reddit r/AutoGPT话题,发现月增速达**217%**
• 专利地图显示,2023年Q2“自主任务规划”相关专利引用量环比+180%
• 人才流动:OpenAI研究员流入初创公司比例从5%飙升至22%
步骤二:政策信号捕捉
美国NIST在《AI风险管理框架》中新增“Agent系统透明度”章节,用词权重较上一版提升**6.3倍**。
步骤三:边缘用户验证
访谈三位用GPT-4自动化报税的自由职业者,发现他们已用“链式提示”模拟多Agent协作,但苦于缺乏可视化编排工具——这成为后来某独角兽产品的PMF切入点。
常见误区与修正清单
误区1:过度依赖单一数据源
修正:建立“数据三角验证”机制,任何趋势需至少三种方法交叉确认。
误区2:混淆“用户想要”与“用户愿意付费”
修正:在趋势验证阶段加入**支付意愿测试**(如预售页A/B测试),避免伪需求。
误区3:忽视技术伦理拐点
修正:当专利或政策出现“伦理审查”关键词频次>3次/月时,立即启动风险评估。
未来三年的研究工具升级方向
• **合成数据模拟**:用生成式AI创建“虚拟用户”进行趋势压力测试
• **链上数据分析**:追踪Web3项目的智能合约调用模式,识别早期生态
• **实时政策流处理**:通过政府API订阅政策更新,触发NLP预警系统
如何从今天开始搭建你的趋势研究系统?
1. 选定一个垂直领域(如“老年科技”)
2. 用免费工具(Google Trends+Lens.org)跑通最小闭环
3. 每月输出一页A4的“信号简报”,强制自己用数据而非直觉论证
4. 加入该领域的Discord/Slack社群,用“边缘用户”视角提问
记住:**趋势研究不是预测未来,而是降低试错成本**。当你能用三种以上独立数据源讲清一个趋势的“为什么现在发生”,你就拥有了比大多数人提前六个月行动的权利。
评论列表