数据分析工具怎么选?先厘清业务场景
很多新人一上来就问“Python和SQL哪个更重要?”其实更关键的问题是:你所在的业务场景到底要解决什么?
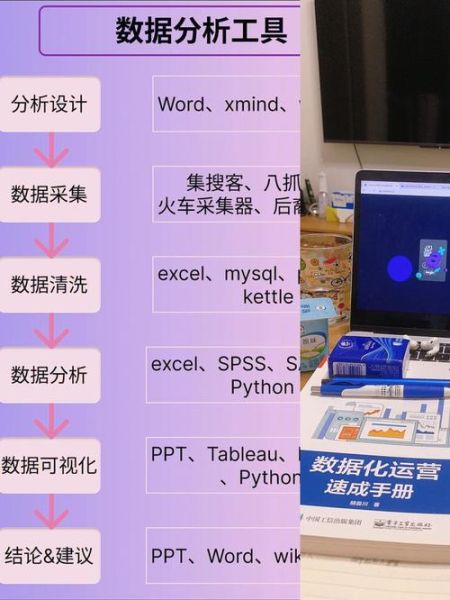
(图片来源网络,侵删)
- 日常报表型需求:Excel+Power BI就能跑通,学习成本低,上线快。
- 实时数据监控:优先考虑Kafka+Flink这类流处理框架,延迟可压到毫秒级。
- 探索式分析:Jupyter Notebook+Python生态(Pandas、Matplotlib)自由度最高。
数据分析岗位需要哪些技能?拆解三大能力域
1. 技术栈:工具只是起点
问:只会SQL能拿offer吗?
答:能,但天花板低。SQL+Python+可视化工具已成标配,再补一门分布式计算(Spark或Hive)才稳。
- SQL:窗口函数、递归CTE、性能调优必须滚瓜烂熟。
- Python:Pandas处理万级以上数据、Scikit-learn跑模型、Airflow写调度。
- 可视化:Tableau做管理层汇报,Superset做运营看板,各取所需。
2. 业务理解:数据只是翻译器
问:为什么技术满分却被业务吐槽?
答:没把数据翻译成业务语言。举个例子:DAU下跌20%,技术视角看是埋点丢失,业务视角可能是竞品投放加大。能用数据讲清“为什么”比“是什么”更值钱。
- 每周跟销售开15分钟晨会,记录他们提到的“异常点”。
- 把SQL结果写成“如果本周不补货,A类门店缺货率将升至35%”这类可执行结论。
3. 沟通表达:让非技术同事听懂
问:汇报总被怼“说人话”怎么办?
答:用“电梯演讲”模板:30秒说清背景、数据洞察、行动建议。比如:
“上周新用户留存下降10%,经分群发现90%来自信息流渠道,建议暂停该渠道投放并追加短信召回预算。”
实战案例:从需求到落地的完整链路
场景:电商大促前预测爆款库存
- 需求澄清:运营要“预测未来7天SKU级销量”,误差需<15%。
- 数据准备:用Python拉取90天历史销量、价格、促销标签,缺失值用同类SKU中位数填充。
- 模型选择:时间序列用Prophet,非线性关系用XGBoost,最终加权融合。
- 结果验证:回溯测试显示误差12%,通过。
- 落地动作:每日早8点自动推送到企业微信,库存组直接按预测值补货。
常见误区与避坑指南
- 误区1:盲目追新技术。Spark很酷,但10万行数据用Pandas更快。
- 误区2:忽视数据质量。埋点错1个字段,模型再高级也白搭。
- 误区3:报告写得太长。管理层只看第一页,把核心图表放前面。
进阶路线:从分析师到数据科学家
问:如何突破35岁危机?
答:横向补业务,纵向深技术。
- 横向:轮岗到供应链、财务、产品,理解全链路数据。
- 纵向:深耕因果推断、强化学习,解决“为什么”和“怎么做”的问题。
资源清单:自学不踩坑
- SQL刷题:LeetCode SQL题库,重点刷Hard级别窗口函数。
- Python实战:Kaggle竞赛“Store Sales”数据集,练时间序列预测。
- 业务书籍:《精益数据分析》+《电商流量运营》,理解业务语言。

(图片来源网络,侵删)
评论列表